
蛋白质组学基础:常用蛋白参考数据库的介绍及选择
蛋白质组学是通过蛋白质鉴定和定量对生物系统中的蛋白质结构和功能进行大规模研究的科学。质谱法在过去几十年作为综合蛋白质组分析的主要工具而被广泛应用,Shot gun/Bottom up是鉴定多肽和蛋白质的主流方法,蛋白质首先被水解成肽段,然后通过质谱法检测带电母离子和碎片离子,记录成谱图数据,再借助数据分析软件进行谱图解析,根据肽段的解析结果和参考数据库,推断蛋白组鉴定结果[1]。因此,如何选择序列参考数据库将直接影响输出的结果。
本期推送主要为大家介绍在常规蛋白质组学数据分析中最常用的两大数据库:Uniprot和NCBI数据库,以及如何将已下载的数据库文件导入PEAKS®软件以进行搜库。欢迎大家转发和收藏!
本期推送主要为大家介绍在常规蛋白质组学数据分析中最常用的两大数据库:Uniprot和NCBI数据库,以及如何将已下载的数据库文件导入PEAKS®软件以进行搜库。欢迎大家转发和收藏!
数据库介绍
1. Uniprot数据库
Uniprot数据库是一个全面的蛋白质资源数据库,为科研工作者提供了丰富的蛋白质序列和功能信息。该数据库由欧洲生物信息学研究所、瑞士和美国蛋白质信息中心等机构共同维护,是一个非营利性的项目,旨在推动蛋白质组学领域的研究发展。数据库整合了多个来源的蛋白质信息,包括Swiss-Prot、TrEMBL和PIR等,形成了一个庞大而统一的蛋白质知识体系。Swiss-Prot包含了经人工注释和验证的蛋白质序列,质量较高,一般分类为“Reviewed”;而TrEMBL中的蛋白是由EMBL-Bank、GenBank 和 DDBJ中的编码序列翻译而来的,因此一般标注为“Unreviewed”。这些数据库涵盖了从细菌到人类等多个物种的蛋白氨基酸序列、基因名称、物种来源等基本信息,为不同领域的研究者提供了宝贵资源。此外,还整合了蛋白质的功能注释、结构信息、翻译后修饰、相互作用网络等内容,这些功能信息有助于研究者深入理解蛋白质在生物体中的角色和作用机制。
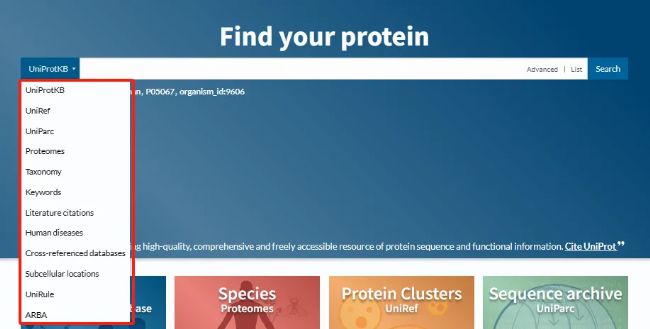
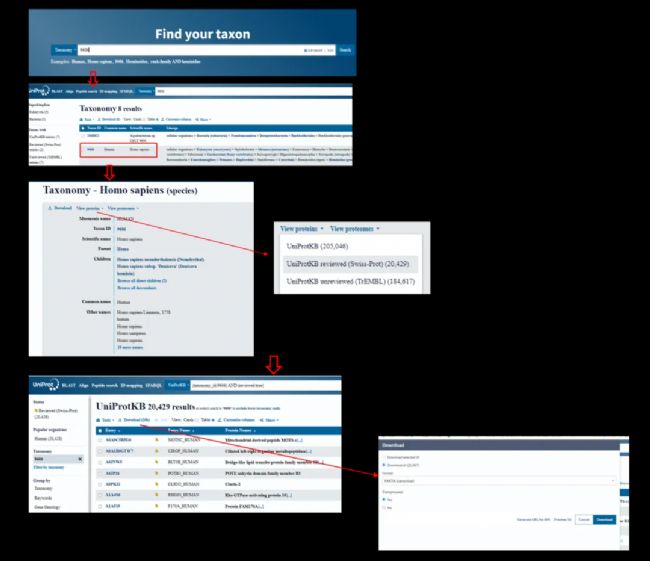
Uniprot数据库还提供了强大的搜索和浏览功能,用户可以通过关键词、序列比对等方式快速定位到感兴趣的蛋白质。在Uniprot网站检索目标蛋白列表时,推荐优先通过Taxonomy分类进行筛选,Proteome分类下的蛋白是来源于完整基因组测序的注释结果,既包含Swiss-Pro,也包含TrEMBLE的蛋白。
Uniprot数据库是一个全面的蛋白质资源数据库,为科研工作者提供了丰富的蛋白质序列和功能信息。该数据库由欧洲生物信息学研究所、瑞士和美国蛋白质信息中心等机构共同维护,是一个非营利性的项目,旨在推动蛋白质组学领域的研究发展。数据库整合了多个来源的蛋白质信息,包括Swiss-Prot、TrEMBL和PIR等,形成了一个庞大而统一的蛋白质知识体系。Swiss-Prot包含了经人工注释和验证的蛋白质序列,质量较高,一般分类为“Reviewed”;而TrEMBL中的蛋白是由EMBL-Bank、GenBank 和 DDBJ中的编码序列翻译而来的,因此一般标注为“Unreviewed”。这些数据库涵盖了从细菌到人类等多个物种的蛋白氨基酸序列、基因名称、物种来源等基本信息,为不同领域的研究者提供了宝贵资源。此外,还整合了蛋白质的功能注释、结构信息、翻译后修饰、相互作用网络等内容,这些功能信息有助于研究者深入理解蛋白质在生物体中的角色和作用机制。
Uniprot数据库还提供了强大的搜索和浏览功能,用户可以通过关键词、序列比对等方式快速定位到感兴趣的蛋白质。在Uniprot网站检索目标蛋白列表时,推荐优先通过Taxonomy分类进行筛选,Proteome分类下的蛋白是来源于完整基因组测序的注释结果,既包含Swiss-Pro,也包含TrEMBLE的蛋白。
2. NCBI数据库
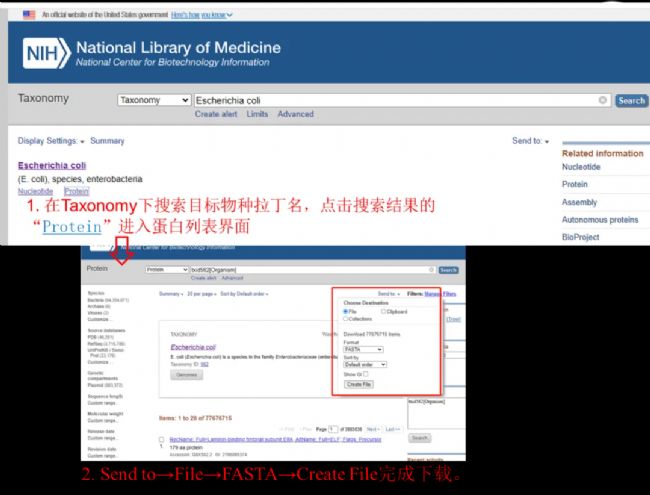
NCBI(National Center for Biotechnology Information)数据库是全球最大的生物信息数据库之一,由美国国立卫生研究院(NIH)下属的美国国家医学图书馆(NLM)建立和维护。蛋白参考序列(RefSeq)只是NCBI数据库组成的一部分,还包括基因序列数据库(GenBank)、生物医学文献数据库(PubMed)、基因数据库(Gene)、结构数据库(Structure)、表型和基因型数据库(dbGaP)等。
RefSeq 类似于 UniProtKB 的中“Proteome”的分类列表,是基于基因组注释结果展示检索结果的的。随着基因组和RNA测序等其他支持数据的更新,RefSeq也会随之更新注释,每个注释版本都会有一个注释报告,其中包含有关底层基因组、新基因组注释、使用的其他信息以及有关更新内容的各种统计数据。RefSeq 的蛋白质序列是以每个物种为单位汇总的,不能像UniProt中那样,通过Taxonomy分类树逐级下载对应的单个fasta文件。如需下载特定物种的fasta数据库,可直接检索具体的taxonomy ID。NCBI下载的FASTA冗余度较高,用户需要使用其他工具进一步合并和去除冗余条目。

如何选择合适的数据库
由于NCBI的参考蛋白信息以基因组注释为主,检索结果的冗余度较高,一般推荐优先使用Uniprot来检索目标物种的参考蛋白序列,并且,要根据实验条件和样本选择最合适的FASTA数据库。数据库过大,会导致搜索空间变大,无关蛋白过多会使得假阳性过高,从而影响“正确”蛋白的鉴定结果。数据库过小,则可能因为蛋白数过少而导致假阴性变高,谱图中本来采集到的蛋白因为不在数据库里面而被漏掉。
对于人、小鼠等常见物种,由于实验数据丰富,被人工校验和注释的蛋白数足够多,因此一般直接在Swiss-Prot下载Reviewed protein fasta即可,但对于非常见物种来说,unreviewed proteins居多,甚至稀有物种本身连基因组注释的信息都极少,此时,可以考虑Taxonomy上一级的参考序列,根据种属同源性进行搜索[2]。
FASTA文件下载步骤及导入PEAKS®
01 Uniprot数据库下载
02 NCBI数据库下载
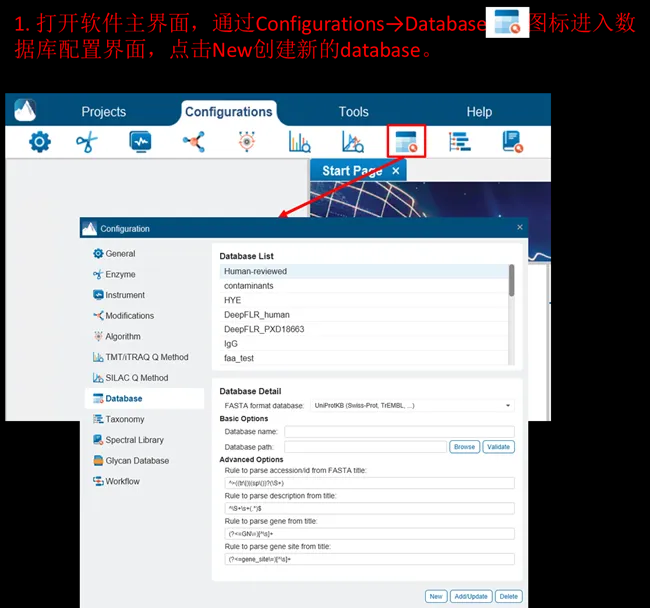
03将FASTA导入PEAKS®
> PEAKS Studio
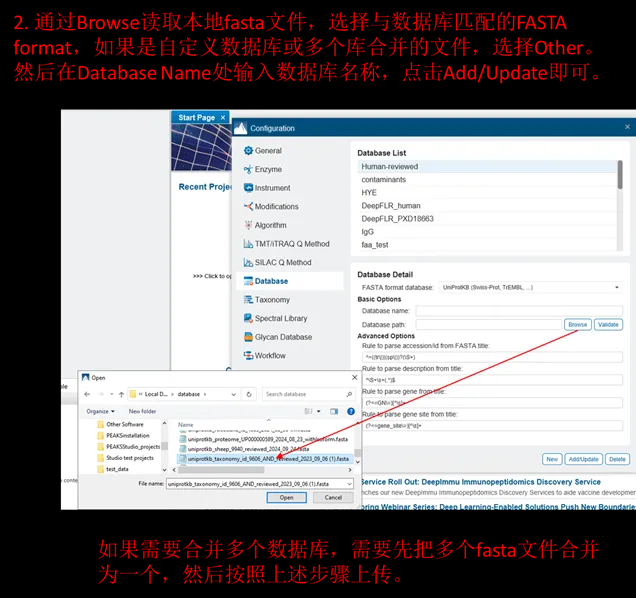
> PEAKS Online
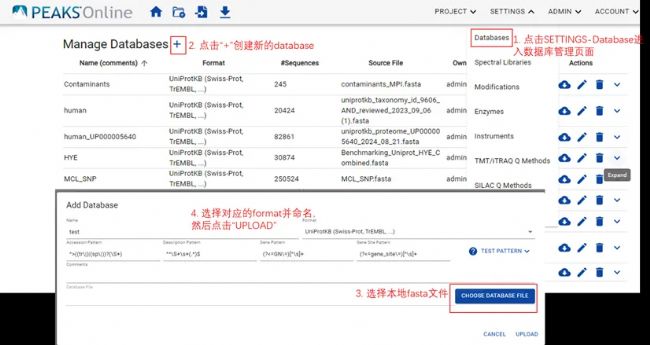
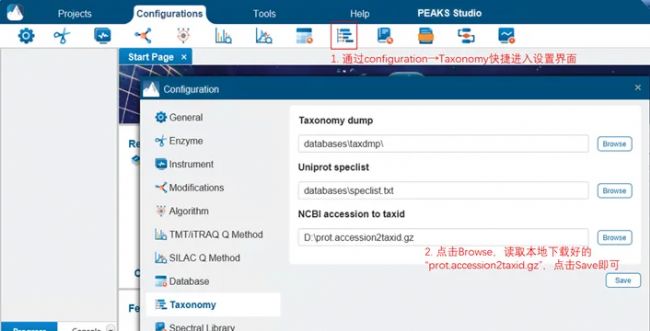
注意:对于NCBI下载的fasta数据库,需要先手动配置对应的taxonomy文件(prot.accession2taxid.gz),配置方法见下图(PEAKS Online直接将该文件copy至安装目录“\peaks-online\taxonomy”路径下即可)。该文件可从NCBI官网下载,也可联系我们获取网盘下载链接。
我们将持续更新蛋白质组学相关基础知识,感兴趣的您敬请持续关注哦!
若您想深入了解PEAKS软件相关功能和应用,欢迎点击下方联系方式提交您的咨询信息!
参考文献
1.Yuming Jiang, Jesse G. Meyer et al. Comprehensive Overview of Bottom-Up Proteomics using Mass Spectrometry. ACS Meas. Sci. Au 2024, 4, 4, 338–417.
2.UniProt. https://www.uniprot.org/help/sequence_origin (accessed 2024-05-07).

-扫码关注-
www.bioinfor.com (EN)
www.deepproteomics.cn(CN)
联系方式:021-60919891;sales-china@bioinfor.com
标签:
蛋白质组学数据库



