
蛋白质组学基础:快速理解DDA与DIA的方法
基于质谱(MS)的蛋白质组学实现了生物样本中蛋白质表达谱的定性定量分析,并且可以辅助研究各种不同状态下蛋白的相互作用。典型的自下而上的蛋白质组学工作流程(图1)包括几个主要步骤:(i) 从所研究的生物样品中提取蛋白质混合物,(ii) 对分离的蛋白质浓度进行测定,(iii) 通过凝胶电泳或液相色谱法对蛋白质进行分离(可选),(iv) 蛋白质酶切, (v) 质谱检测,(vi) 数据库搜索蛋白质鉴定。
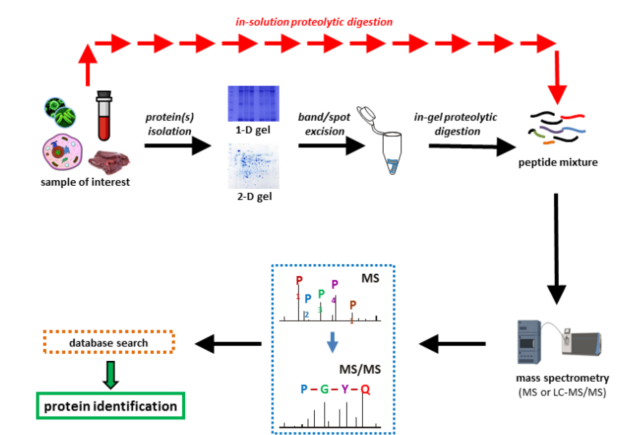
图1 自下而上的蛋白质组学流程[1]
近年来,许多质谱方法从数据依赖采集(DDA)过渡到数据非依赖采集(DIA)。虽然DIA灵敏度和覆盖度高,但并不是所有的研究都适合,很多情况下DDA反而更合适。对于很多初涉质谱蛋白质组学领域的研究者来说,往往对DDA和DIA的方法难以理解,因此,本期推送我们给大家详细介绍一下这两种不同的质谱采集方法。
首先,我们要对质谱采集信号的过程有个简单的概念。简言之,我们的肽段在经过液相(LC)洗脱之后,被电离雾化成为带电离子(即母离子,precursor)进入质谱内部,首先经过一级母离子的全扫描(即survey scan),得到MS1谱图,然后针对这些扫描到的母离子,选择哪些离子去做下一步的MS2碎裂和扫描,就涉及了DDA还是DIA的问题。
DDA
DDA是Data Dependent Acquisition的缩写,即数据依赖采集,指的是在一个循环内,选取离子强度Top N的MS1母离子进行MS2碎裂与扫描(原理示意见图2),N在质谱采集方法中进行设定,一般为10-20。随着肽段流出,完成整个液相梯度内的谱图采集,产生的下机数据随后采用相应的软件完成肽段和蛋白的鉴定和定量。
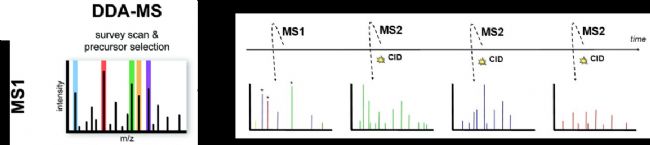
图2 DDA谱图采集示意图
DDA是质谱采集方法的一种大类,与不同的实验方法结合,又可以产生不同的数据类型,满足不同的实验需求,包括常规的定性、非标记定量(LFQ)、标记定量(TMT/SILAC等)。
DDA的优势在于实验方法简单,其谱图的复杂性较低,不仅可以进行标准的搜库分析,还可以进行large search space搜索,如PTM search、酶切半特异性及非特异性搜索,甚至开放搜索。针对未知样本,则需要进行从头测序(de novo)分析。DDA的局限性在于检测动态范围有限,易损失低丰度的离子,从而产生较多的定量缺失值,导致重现性不稳定,对于复杂样本的全蛋白组鉴定深度不够。
针对DDA数据,PEAKS®软件既可以针对未知样本单独进行从头测序分析,也可以进行de novo辅助的搜库分析(DB search),以及非标记定量和各种标记定量分析。此外,PEAKS®还整合了独有的免疫肽组分析、未知翻译后修饰及突变位点检索、完整糖肽鉴定(Studio Only)(图3),满足绝大部分DDA数据的定性、定量分析需求。
DDA的优势在于实验方法简单,其谱图的复杂性较低,不仅可以进行标准的搜库分析,还可以进行large search space搜索,如PTM search、酶切半特异性及非特异性搜索,甚至开放搜索。针对未知样本,则需要进行从头测序(de novo)分析。DDA的局限性在于检测动态范围有限,易损失低丰度的离子,从而产生较多的定量缺失值,导致重现性不稳定,对于复杂样本的全蛋白组鉴定深度不够。
针对DDA数据,PEAKS®软件既可以针对未知样本单独进行从头测序分析,也可以进行de novo辅助的搜库分析(DB search),以及非标记定量和各种标记定量分析。此外,PEAKS®还整合了独有的免疫肽组分析、未知翻译后修饰及突变位点检索、完整糖肽鉴定(Studio Only)(图3),满足绝大部分DDA数据的定性、定量分析需求。

图3 PEAKS®软件DDA分析工作流
DIA
DIA的全称是Data Independent Acquisition,即数据非依赖采集,另一种说法为sequential window Acquisition of All Theoretical Fragment ions(SWATH),简单理解就是二级的采集不依赖一级信号离子的选择,而是把MS1所有扫描到的母离子按照m/z划分为若干个小的窗口,对每个窗口内的所有母离子进行二级碎裂和扫描,可以认为是无差别“攻击”(原理示意见图4)。
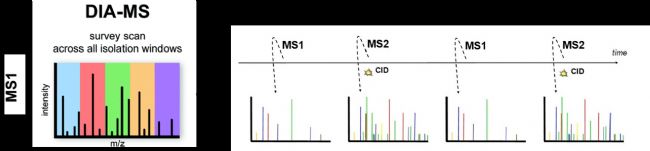
图4 DIA谱图采集示意图
DIA的谱图复杂度要远远高于DDA,因此在DIA方法开发的初期,数据分析基本上依赖于谱图库搜索(Spectral library)的方法,即要事先通过多组份分馏的方法将所有待分析样本的混合物进行高pH液相色谱分离,然后通过DDA的采集方法获得建库数据,使用建库数据的鉴定结果作为谱图库,然后进行DIA数据的定性和定量分析。谱图库搜索速度快、准确性高,但也存在一些局限,比如建库深度不够,建库需要额外的样品消耗、成本和机时等。随着谱图解析算法的发展,针对DIA的数据使用理论参考序列库进行直接解谱已经得到了广泛应用,深度学习模型的引入,大大提高了DIA直接数据库搜索的谱图解析率和准确性,也使得DIA de novo分析成为可能[2]。
DIA的优势在于对样本中所有多肽的无偏检测,检测动态范围广,突破了DDA对低丰度样本检测的局限,非常适合大规模、微量样本的蛋白质组学研究。但DIA对质谱硬件和软件的要求比DDA更高,综合成本相应就有所增加,此外存在很多翻译后修饰,也会导致谱图更加复杂。
PEAKS®软件支持DIA数据的谱图库搜索(Spectral Library search)、直接数据库搜索(direct DB search)、DIA数据的从头测序(DIA de novo)分析之外,还独有DIA免疫肽组的定性定量分析功能,也支持hybrid-DIA数据分析(图5)。
DIA的优势在于对样本中所有多肽的无偏检测,检测动态范围广,突破了DDA对低丰度样本检测的局限,非常适合大规模、微量样本的蛋白质组学研究。但DIA对质谱硬件和软件的要求比DDA更高,综合成本相应就有所增加,此外存在很多翻译后修饰,也会导致谱图更加复杂。
PEAKS®软件支持DIA数据的谱图库搜索(Spectral Library search)、直接数据库搜索(direct DB search)、DIA数据的从头测序(DIA de novo)分析之外,还独有DIA免疫肽组的定性定量分析功能,也支持hybrid-DIA数据分析(图5)。


图5 PEAKS®软件DIA数据分析工作流
DDA or DIA, that is the question.
作为质谱蛋白质组学研究的两大类方法,DDA和DIA各有优缺点,并没有绝对的好坏之分,适合的才是最好的。DIA更加适合进行需要高覆盖率和定量准确性的大规模蛋白质组学研究。Rebecca C. Poulos等 (2020) [3]将卵巢癌组织、前列腺癌组织和酵母蛋白按照不同比例混合,以HEK293T细胞蛋白作为对照,历时4个月,在6台质谱仪上共采集了1560针DIA数据,期间还穿插了5000多针其他样品的数据采集。数据分析结果显示,在短时间内获得的DIA-MS数据重现性和定量准确性均较高,但随着采集间隔时间的延长和仪器性能的变化,CV值会累积增加,因此对于大队列、长时间的数据采集,仍需要开发合适的归一化校正方法。
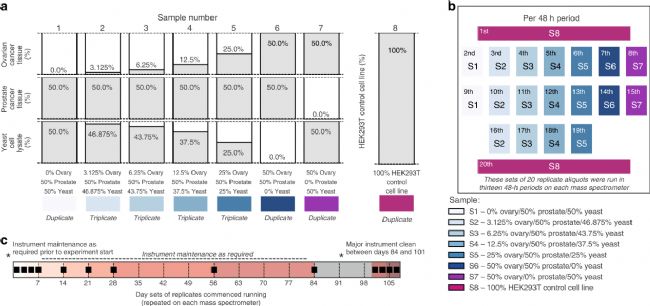
(Rebecca C. Poulos等,2020)
DDA 更加适合需要高灵敏度和准确性的小规模研究,尤其是对于纯化蛋白、翻译后修饰组学的研究。此外,DDA可搭配各种不同的标记实验方法,提升定量的稳定性。Matthias Mann等 (2023)[4]使用DDA 分析了小鼠心脏、骨骼肌等7种组织线粒体的全蛋白组和磷酸化蛋白组,共鉴定到1266个线粒体蛋白,超过MitoCarta 3.0数据库中的92%,且定量CV小于20%。线粒体磷酸化蛋白质组表现出广泛的线粒体内磷酸化,且与融合和裂变的组织特异性调节有关。该研究是 DDA 对细胞器蛋白质组及磷酸化修饰高灵敏鉴定的典型示例。
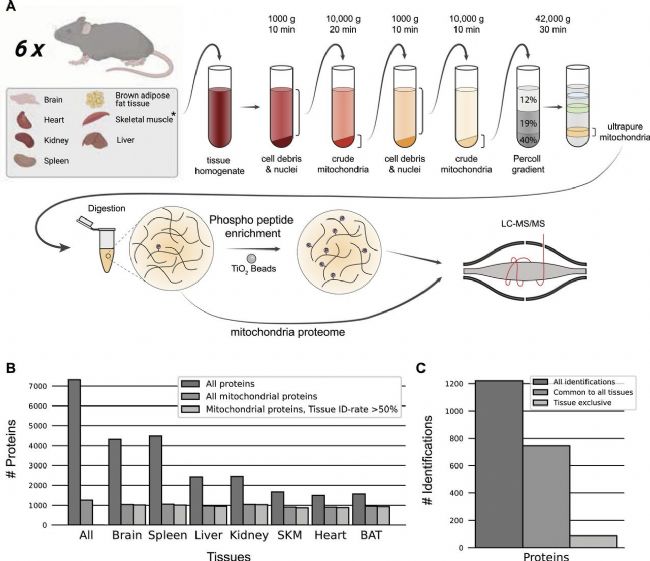
(Matthias Mann等,2023)
划重点
PEAKS®提供DDA和DIA兼容的数据分析完整解决方案,一站式满足发现和靶向质谱蛋白质组学领域的分析需求。点击PEAKS Studio--兼容DDA和DIA,发现与靶向蛋白质组学质谱数据一站式软件平台了解更多PEAKS®软件的相关功能,也可通过电话021-60919891、邮件sales-china@bioinfor.com与我们联系或下方“阅读原文”提交您的咨询信息!
参考文献
参考文献
- Dupree, E.J.; Jayathirtha, M.; Yorkey, H.; Mihasan, M.; Petre, B.A.; Darie, C.C. A Critical Review of Bottom-Up Proteomics: The Good, the Bad, and the Future of This Field. Proteomes 2020, 8, 14. https://doi.org/10.3390/proteomes8030014
- Tran, N.H., Qiao, R., Xin, L. et al. Deep learning enables de novo peptide sequencing from data-independent-acquisition mass spectrometry. Nat Methods 16, 63–66 (2019). https://doi.org/10.1038/s41592-018-0260-3
- Poulos, R.C., Hains, P.G., Shah, R. et al. Strategies to enable large-scale proteomics for reproducible research. Nat Commun 11, 3793 (2020). https://doi.org/10.1038/s41467-020-17641-3
- Hansen, F. M., Kremer, L. S., Karayel, O., Bludau, I., Larsson, N.-G., Kühl, I., & Mann, M. (2024). Mitochondrial phosphoproteomes are functionally specialized across tissues. Life Science Alliance, 7(2), e202302147. doi:10.26508/lsa.202302147

-扫码关注-
www.bioinfor.com (EN)
www.deepproteomics.cn(CN)
作为生物信息学的领军企业,BSI专注于蛋白质组学和生物药领域,通过机器学习和先进算法提供世界领先的质谱数据分析软件和蛋白质组学服务解决方案,以推进生物学研究和药物发现。我们通过基于AI的计算方案,为您提供对蛋白质组学、基因组学和医学的卓越洞见。旗下著名的PEAKS系列软件在全世界拥有数千家学术和工业用户,包括:PEAKS Studio,PEAKS Online,PEAKS GlycanFinder, PEAKS AB及抗体综合表征服务等。
联系方式:021-60919891;sales-china@bioinfor.com



